いよいよ最終課題! データ・サイエンスとコンピュータ・ビジョン

こんにちは! アメリカのブラウン大学に留学中のKentaです!
今回は、前の学期にとった「データ・サイエンス」と「コンピュータ・ビジョン」の最終プロジェクトについて書きたいと思います。これらの科目の内容については、この記事を参照してください。
データ・サイエンスの最終課題
データ・サイエンスの最終プロジェクトは4人一組で行いました。お題はかなり融通がきくものになっていて、以下の4つを含んでいれば大丈夫でした。
- 単純すぎないデータベースの作成
- 機械学習モデルの実装
- 仮説の実証(帰無仮説を否定するかしないか)
- 結果を示したグラフなどの作成
グループで話し合った結果、僕たちは「コロナウィルスによって影響を受けたUberやLyftといったライドシェアサービスの価格を予想する機械学習モデルを実装する」というアイデアで進めることにしました。
まずデータベースの作成ですが、Chicago Data Portalが運営しているサイトのオープン・データセットを使うことにしました。このサイトにはすでにシカゴのコロナ感染者数や死者数を含むデータセットとライドシェアサービスの運行履歴のデータセットがあったので、それらを読み込み、2つのデータセットを組み合わせて1つのデータベースにしました。
機械学習モデルも3種類ほど用意しました。複雑になるので細かくは説明しませんが、選ぶ際にデータの分布を調べて、それを基準にしました。ライドシェアサービスの値段を予測するのに使ったモデルはLinear Regression、KMeans + SVM、そして LSTMです。下の画像が3つのモデルの予想です。
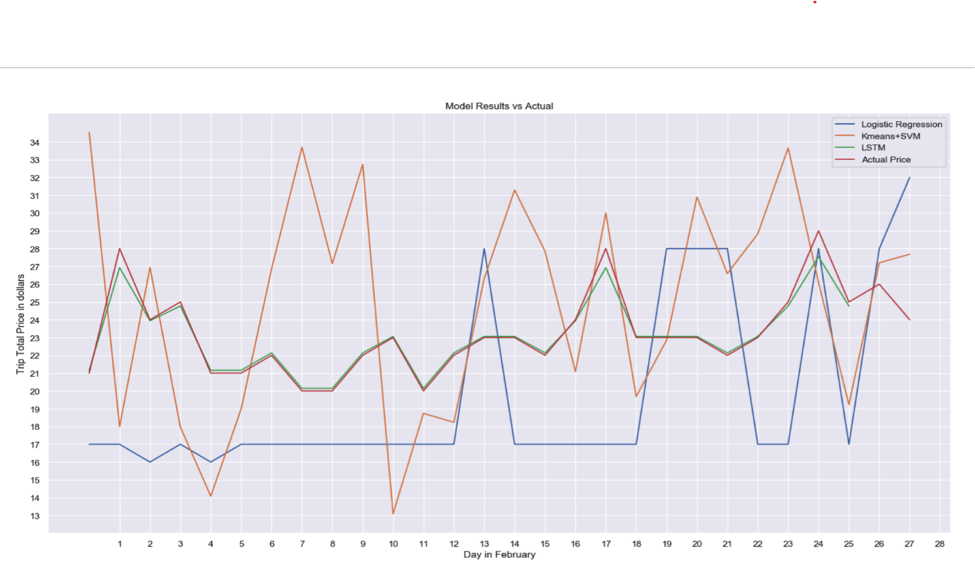
モデルの予想
赤い線が実際の値段、緑がLSTM、黄色がKMeans+SVM、そして青がLogistic Regressionになっています。
仮説の検証においては3つの仮説を用意しました。
- 帰無仮説① コロナの陽性患者数とライドシェアサービスの値段は独立関係である
- 帰無仮説② ライドシェアサービスの値段は定常時系列である
- 帰無仮説③ 私たちのデータセットは正規分布である
この帰無仮説を統計のテストを使って、否定したりしました。
最後にグラフですが、上の結果のグラフに加え、僕たちの使ったデータセットの分布を調べた際に、以下のグラフを作成しました。
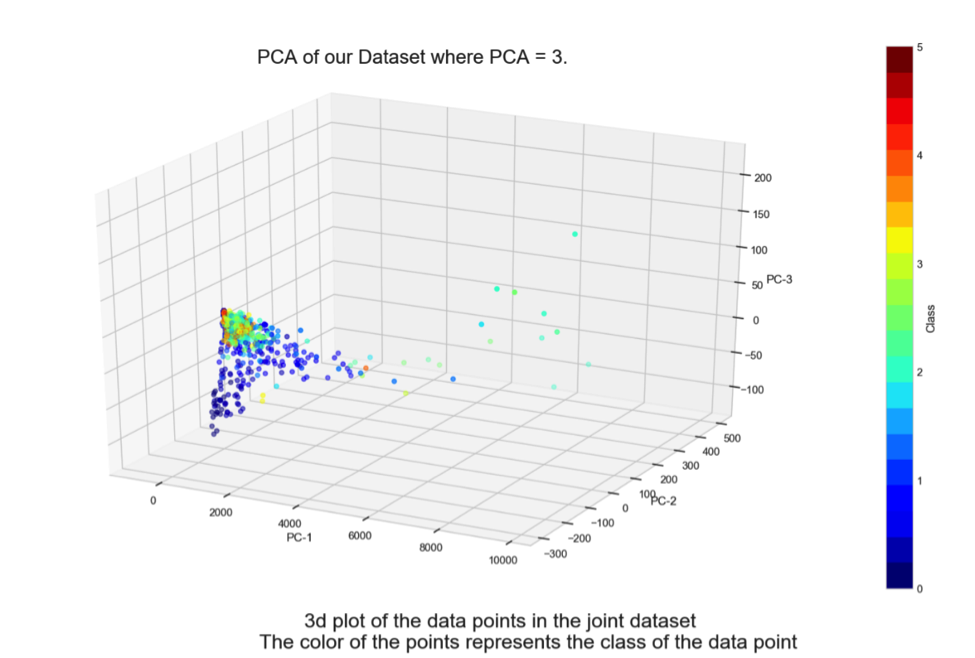
データの分布
上の図から、データは1か所に集中しているように見えますね。この観察を基準に、どの機械学習のモデルを使うかを決めました。
このデータ・サイエンスの最終課題は、データの採集からプロセス、そして応用まですべて1から自分たちが行ったので、とてもいい経験になりました。また少し自信もついたと思います。
コンピュータ・ビジョンの最終課題
次にコンピュータ・ビジョンの最終課題を紹介したいと思います。
コンピュータ・ビジョンの科目とはそもそも何なのかというと、「機械がどのようにして現実世界を認識するかを勉強するもの」という認識でいいと思います。
僕たちの最終課題も、「授業で勉強したことを駆使して、コンピュータ・ビジョンに関係するテーマを選び、発表する」というとてもオープンなものでした。
チームは3人で組みます。3時間ほど話し合った結果、最近話題のモーフィング動画をつくろう! ということで合意に至りました。
みなさん、モーフィングをご存じですか?
顔を老けさせたり、若返らせたり、建物を別の建物に変形させたりといったのを見たことがあるかもしれません。これをモーフィングといいます。
実際は2つの写真を用意して、その中間点となる多くの写真をつなぎ合わせてこのような動画をつくります。下の画像がいい例になると思います。

モーフィングの例
ここで1つ注目してほしいのが、どの中間地点をとってもそれが写真として成り立っているということです。上の例では人間の顔を使用していますが、どの中間地点を見ても、人間の顔ですよね? そういった感じです。
このモーフィングをつくるにあたって必要なものがあります。それは「中間地点として成り立っている(上の人間の顔のように)、中間写真たち」です。
では実際に僕たちがどのようにしてこの中間写真を得たのか、説明しましょう。
まず前提として、上の画像がそうであるように、モーフィングの始まりと終わりの写真が同じ物体という制約を設けさせていただきます。
そして深層学習のモデルを1つ使うのですが、今回は写真を生成するということで、Generative Adversarial Network (GAN)というものを使います。
簡単に説明すると、GANには2つのパーツがあります。
これを警察官と偽札業者にたとえます。
偽札業者の仕事は、警察官をだませるほど精巧な偽札をつくることです。警察の仕事は、偽札業者のつくった偽札と本物のお札を見分けることです。
最初は偽札業者はテクニックを所持していないために、警察にすぐに見破られてしまいます。しかし、回を重ねるごとに、次第にテクニックは上達し、遂には警察も見破れない偽札をつくれるようになります。
このようにして、GANは現実にあるような物体(本当は存在しないもの)を生成することができるのです。
僕たちのプロジェクトではこのGANの偽札業者に当たる部分を使いました。
事前に業者には、ある1つの物体を生成するようにお願いします(顔、猫、車など)。そして、この業者にベクトルを代入すると、写真が生成されるというカラクリです。下の写真が、無作為に抽出したベクトルを使って生成されたものです。


生成された写真
ここで問題となるのが、これを活かしてどのようにして中間写真たちを獲得するかです。もっと詳しくいうと、モーフィングの始まりと終わりの写真のベクトルをどのようにして入手するかです。この2つさえあれば、この数式を使うことで、中間地点のベクトルを入手できるのです。w1を始まりの写真のベクトル、w2を終わりの写真のベクトルとし、λは0から1の値をとるとすると
w=λw1+(1- λ)w2
まあ、これを使えば複数の中間地点の写真が得られるんだなぁ、くらいに理解してもらえれば幸いです。
最終的に、僕たちは始まりの写真と終わりの写真のベクトルを得るために2つのアプローチを検証し、それぞれから得られたモーフィングの比較をすることによって、どちらのアプローチがより有効かというのを研究会で発表しました。
こちらが研究会での発表は、すべてのグループが下のようなポスターを作成し、ブースを設けます。会場ではいろいろなブースを訪れて、さまざまな最終課題を詳しく学ぶことができました。おもしろいものは、たとえば:
- 写真にテーマづけできる機械学習モデル
- 写真を分析して、どの有名人に似ているか格づけする機械学習モデル
などです。
いずれも実際にデモが準備されていて、実際に自分の顔を使って検証することができたので、生でその結果を見られたのはとてもおもしろかったです。
僕たちのブースはというと、かなり好評でした。デモでは好きな写真2枚を使ったモーフィングを実施したのですが、ブースに訪れた人たちもとても楽しんでくれたみたいでよかったです。
テーマづけ

僕たちのブース
そして最終成果物として、僕たちのグループは論文のようなものを作成しました。数式や、全体的な結果などをまとめたものになっています。
今回の記事はここまでです! 少し技術的すぎたかもしれませんが、どうしても僕が勉強していることを共有したかったのでお許しください! ではまた次回の記事でお会いしましょう!
Kentaくんの記事一覧
- 第1回 どうしていま、アメリカの大学に留学するのか?
- 第2回 留学先としてリベラルアーツ・カレッジを選んだ理由
- 第3回 まさか!? ブラウン大学から合格通知が!
- 第4回 アメリカの大学受験。「僕はこういう人間」と伝えるために
- 第5回 100%の自分自身を表現。アメリカの大学への出願エッセーの書きかた
- 第6回 アメリカ大学受験のカギを握る「推薦状」と「大学個別のエッセー課題」について
- 第7回 いよいよ渡米! 2つのスーツケースと共に、ブラウン大学に向けて飛び立ちます!
- 第8回 ついにブラウン大学に到着! 入寮からPCR検査まで
- 第9回 PCR検査は週に2回。ブラウン大学の隔離生活
- 第10回 ブラウン大学の日常。寮生活から勉強、週末の過ごしかたまで
- 第11回 ブラウン大学で初の期末試験! 次の学期にとる科目も思案中
- 第12回 ブラウン大学の期末試験。何が問われ、どれだけの勉強が求められるのか?
- 第13回 寝ずに勉強! 留学して初の期末試験。その結果は?
- 第14回 ブラウン大学生活の余暇。ボストンへ! ニューヨークへ!
- 第15回 ブラウン大学の夏学期。今期の履修科目を紹介します!
- 第16回 コロナが収束しつつあるブラウン大学。普通の学生生活が戻るか?
- 第17回 ブラウン大学1年生を締めくくる期末試験。その内容を科目ごとに紹介します!
- 第18回 ブラウン大学で1年を終えて。来年度に向けて寮と科目を選びました!
- 第19回 ブラウン大学の1年度が終わり、夏休みに向けた準備を開始!
- 第20回 ボストンからオレゴンへ。鉄道でアメリカ横断の1人旅
- 第21回 オレゴン州ポートランドのホストファミリーと再会! アメリカの「家族」のありがたさを実感
- 第22回 オレゴンからロス、そしてミシガンからボストンへ。夏休みも終わりです
- 第23回 いま話題のディープラーニング。ブラウン大学の「深層学習」の課題を紹介します!
- 第24回 250時間かかった科目も! コンピュータのクラスの課題とは?
- 第25回 コロナ禍に冬休みで帰国。思わぬ事態が!
- 第26回 ブラウン大学のコンピュータ・サイエンス。機械学習からサイバーセキュリティまで
- 第27回 TAからランニング、ハワイ旅行まで。授業以外にも充実の大学留学生活を紹介!
【あわせて読みたい関連記事】





しっかり分かる
留学講演会
>
まずは
資料請求
>